Batch
Digifi’s batch feature equips an analyst with scheduled data services for re-occurring data management and scoring tasks. Like the autoload feature, batch processing provides self-service data prep to accelerate the most time-consuming (and sometimes most tedious) aspects of analysis. The result is a significant improvement in productivity, accuracy, and reliability, especially when supporting deployments.
Requirements
Batch processing only works with a comma separated (CSV) file format. The required file naming convention is [your_file_name_YYYYMMDD].csv where YYYY denotes the 4-digit year, MM the 2-digit month, and DD the 2-digit day.
Snapshot Dates
Every file and row loaded into the database is tagged with a `data_date` value representing the file extract date of the data. The YYYYMMDD portion of your file name represents this date.
How it Works
Batch mode reads in an array of modules for processing. A series of data management routines is run for each module according to its given props file configuration settings. Unlike autoload, batch processing can be scheduled. This is usually preferred when processing daily or weekly files or when scoring data at regular intervals.
The command for running a batch process is:
where run date is a YYYYMMDD formatted date. The `extractcall` script will load the module list specified in the ETL config file. The naming convention for the space separated module list is:
where YYYYMMDD is an optional parameter denoting the file extract date of the data. Batch processing will snapshot your data with the run date passed to `extractcall` if the YYYYMMDD date parameter is absent in the module list.
For example, using the command
with a module list defined as
would process the daily stock and fundamental files for 10/5/15 and the end-of-quarter split file for 9/30/15.
Props File
A props file contains module specific settings for database object names, raw data field names, and what type of database load process should be used. Create a props file using the command:
where the module name denotes the uppercase representation of your file name and the database name is the database you want to load to. The default configuration for a module is as follows:
After creating a new props file, use a text editor to customize the settings.
Load Type
`Load Type` is a parameter setting in the props file. It has three options:
Digifi ETL is smart enough to add new columns to the database object or ignore columns that are missing in your file. Accordingly, `insert` is usually sufficient. However, if you have field names that are constantly changing or a re-occurring analysis that does not require historical snapshotting, then `drop` is the preferred option.
Setting Up a Batch Process
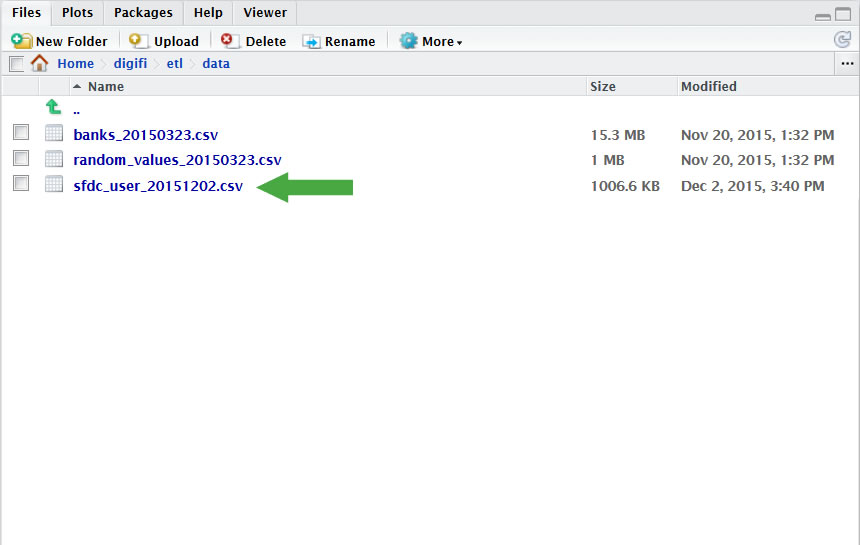
- Connect via RStudio. Click here for help.
- Navigate to: digifi > etl > data
- Click ‘Upload`
- Click `Browse` to locate the file
- Click `OK`
- (For this example, we will use the existing `random values` file and a `sfdc user` file uploaded with today’s date.)
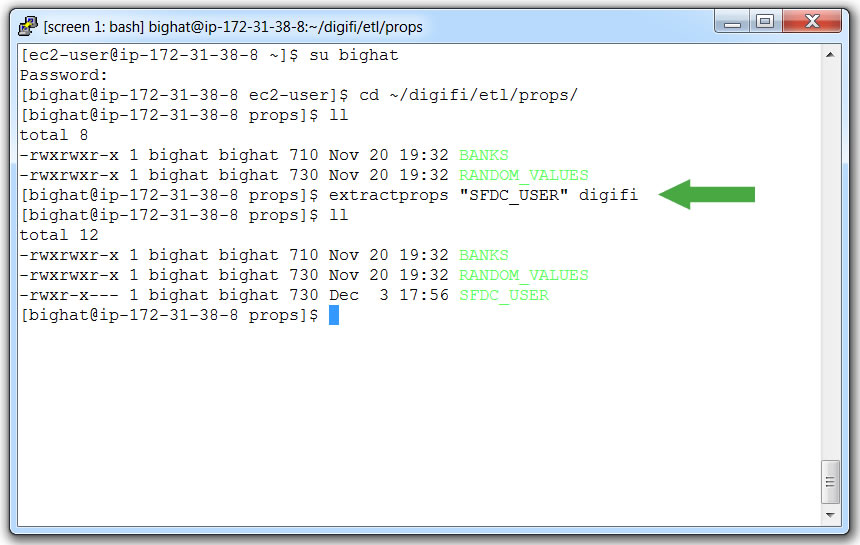
- Switch over to a SSH terminal
- Login as `bighat` with command:
su bighat - Go to the props directory with command:
cd ~/digifi/etl/props/ - Create a props file with command:
extractcall “SFDC_USER” digifi - Note how the `SFDC_USER` props file is now present
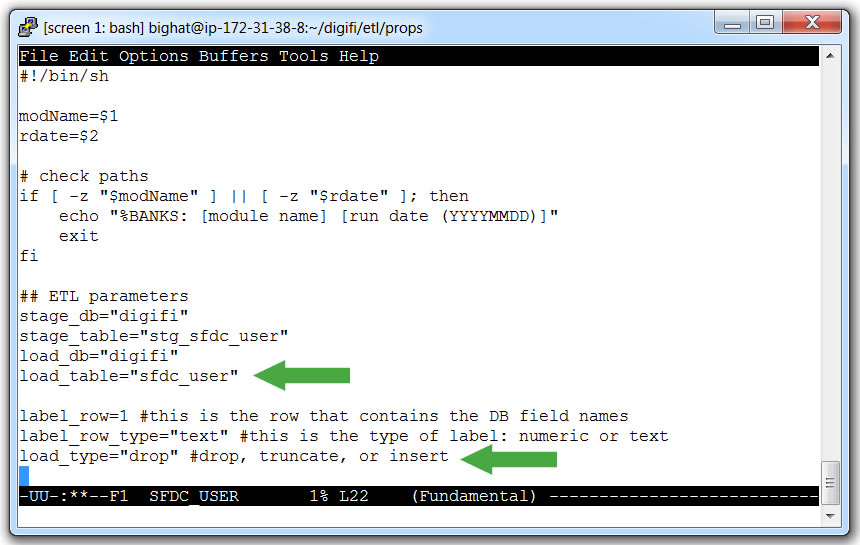
- Open `SFDC_USER` with a text editor
- Change the load table to `sfdc_user`
- Change the load type to `drop`
- Save and close
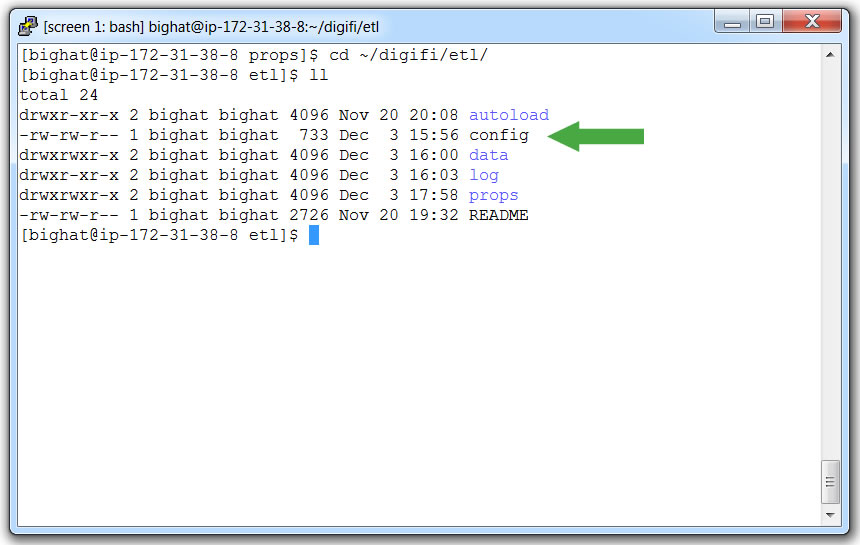
- Go to the etl directory with command:
cd ~/digifi/etl - Open `config` with a text editor
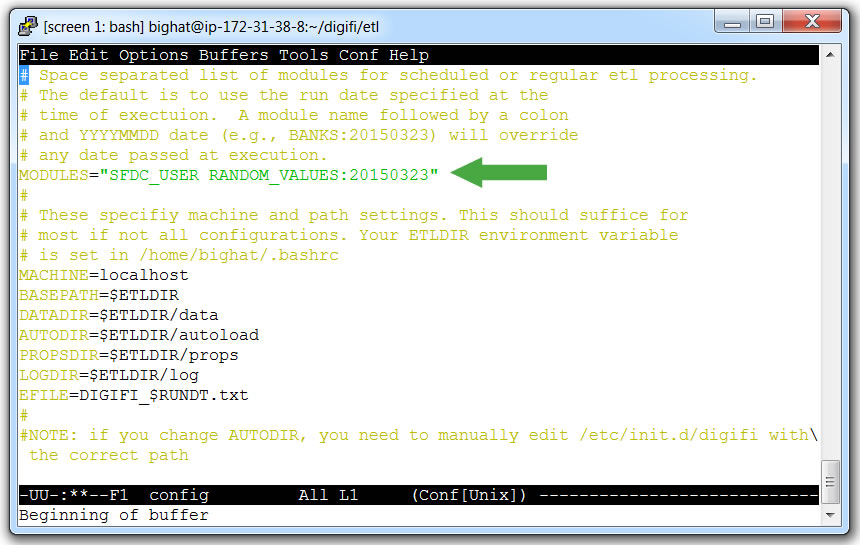
- Add modules to the `MODULES` array
- (Make sure the list is separated by spaces)
- (Also make sure modules without dates are listed first)
- Save and close
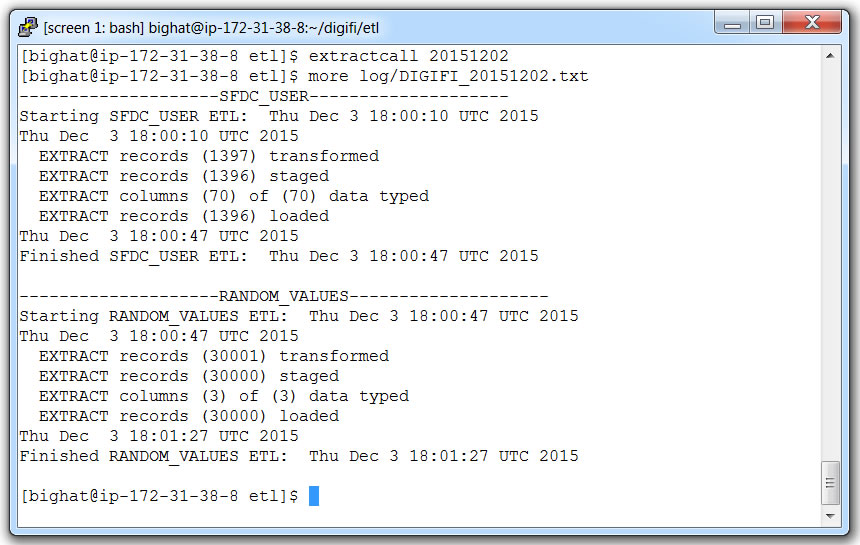
- Run the batch process with command:
extractcall 20151202 - View the daily process log with command:
more ~/digifi/etl/log/DIGIFI_20151202.txt
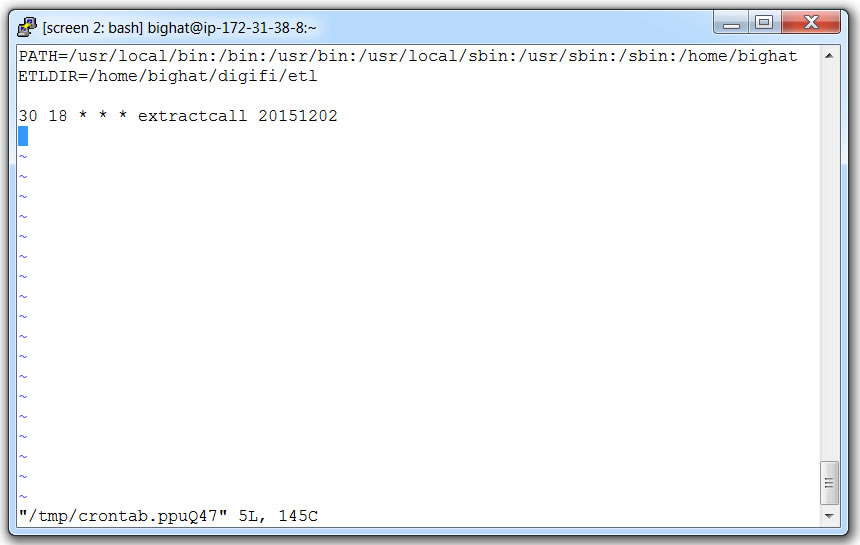
- Schedule the batch process with command:
crontab -e - Copy the following lines and paste into the editor:
PATH=/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/bighat
ETLDIR=/home/bighat/digifi/etl30 18 * * * extractcall 20151202
- Save and close
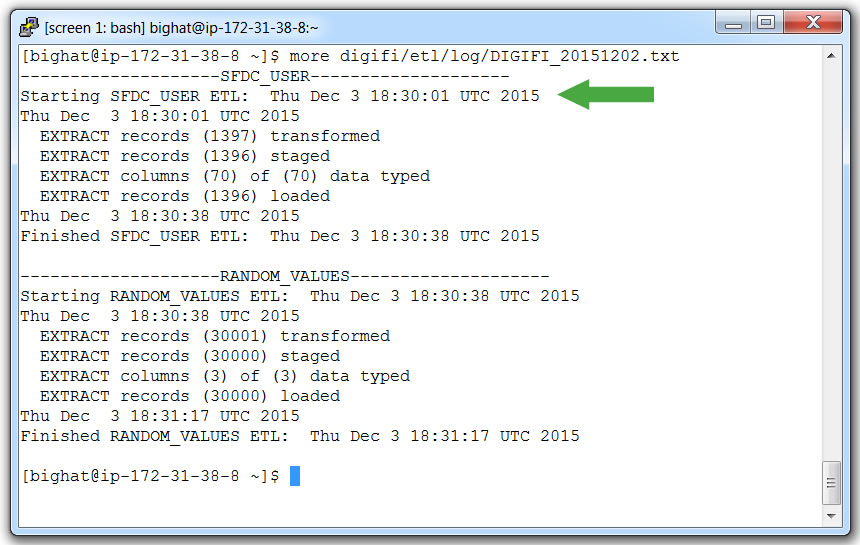
- View the daily process log again with command:
more ~/digifi/etl/log/DIGIFI_20151202.txt - Note how processing started on schedule
- Learn more about crontab here.